Acquiring data
Not so many years ago, data was hard to obtain. Often journalists would have to painstakingly compile their own datasets from paper records. The Internet has changed the game. Today, many government and other public databases can now be queried online, and the results of those searches downloaded. Other datasets can be downloaded in their entirety.
The main problem today is usually not finding relevant data, but in working out whether it can be trusted, spotting and correcting errors and inconsistencies, and getting it in the right format for analysis and visualization.
In this class, we will cover some tips and tricks for finding the data you need online, getting it onto your computer, and how to recognize and clean “dirty” data. We will also review some common data formats, and learn how to convert from one to another.
The data we will use
Download the data for this class from here, unzip the folder and place it on your desktop. It contains the following files:
urls.txtlinks scraped from State of New York site documenting disciplinary actions against doctors.ny_dr_discip_urls.htmlweb page with a table giving links to pages documenting individual disciplinary actions against New York doctors.
Understand common data formats
CSV is just one variant of a “delimited” text file, in which the fields or columns in a table of data are separated by commas (hence comma-separated values, or CSV) or another character such as a tab. You may also encounter “fixed width” text files, in which the fields are lined up, with each located a specified number of characters across each row. Spreadsheets such as Libre Office Calc or Microsoft Excel can import fixed-width files, which you can then export in a delimited format for use in other software.
Text files are great for transferring data from one software application to another during analysis and visualisation, but other formats that are easier for machines to read are typically used when transferring data between computers online.
JSON, or JavaScript Object Notation, treats data as a series of “objects,” which begin and end with curly brackets. Each object in turn contains a series of name-value pairs. There is a colon between the name and value in each pair, and the pairs separated by commas.
Here, for example, are the first few rows of a simple dataset relating to a controversial theory claiming that the extent to which a country has developed a democratic political system is driven largely by the historical prevalence of infectious disease:
[{"country":"Bahrain","income_group":"High income: non-OECD","democ_score":45.6,"infect_rate":23},
{"country":"Bahamas, The","income_group":"High income: non-OECD","democ_score":48.4,"infect_rate":24},
{"country":"Qatar","income_group":"High income: non-OECD","democ_score":50.4,"infect_rate":24},
{"country":"Latvia","income_group":"High income: non-OECD","democ_score":52.8,"infect_rate":25},
{"country":"Barbados","income_group":"High income: non-OECD","democ_score":46,"infect_rate":26}]
XML, or Extensible Markup Language, is another format often used to move data around online. For example, the RSS feeds through which you can subscribe to content from blogs and websites using a reader such as Feedly are formatted in XML.
In XML data is structured by enclosing values within “tags,” similar to those used to code different elements on a web page in HTML. Here is that same data in XML format:
<?xml version="1.0" encoding="UTF-8"?>
<rows>
<row country="Bahrain" income_group="High income: non-OECD" democ_score="45.6" infect_rate="23" ></row>
<row country="Bahamas, The" income_group="High income: non-OECD" democ_score="48.4" infect_rate="24" ></row>
<row country="Qatar" income_group="High income: non-OECD" democ_score="50.4" infect_rate="24" ></row>
<row country="Latvia" income_group="High income: non-OECD" democ_score="52.8" infect_rate="25" ></row>
<row country="Barbados" income_group="High income: non-OECD" democ_score="46" infect_rate="26" ></row>
</rows>
Data portals
Life is much easier if you can find everything you need in one place. The main effort to centralize access to data by the U.S. federal government is Data.gov. You can search for data from the home page, or follow the Data and Topics links from the top menu.
Be warned, however, that Data.gov is a work in progress, and does not contain all of the U.S. government’s data. Some of the most useful datasets are still only available on the websites of individual federal agencies. FedStats has links to agencies with with data collections.
It is worth familiarizing yourself with the main government agencies that have responsibility for the beats you are interested in, and the datasets they maintain.
We talked about some science-specific data sources in the previous class.
Here are some other examples of agencies with useful data:
U.S. Census Bureau: population, demographic, economic and other data, including trade and manufacturing statistics. The American FactFinder is especially useful for summary data about specific geographical areas. As well as running the decadal national census, the bureau operates other surveys, which provide more detailed information from representative samples of the U.S. population, including the Current Population Survey (run jointly with the Bureau of Labor Statistics, see below) and the American Community Survey.
Bureau of Labor Statistics: employment and unemployment, workplace injuries, time use, pay and consumer spending, including the Consumer Price Index, a key measure of inflation. Browse its datasets here.
Bureau of Justice Statistics: crime and law enforcement. Here is its full list of data collections. The National Crime Victimization Survey is an especially useful resource, which together with the Federal Bureau of Investigation’s Uniform Crime Reporting program provides the best national data on crime.
Centers for Disease Control and Prevention: The WONDER online databases provide a wealth of information, including on causes of death. Other health datasets are available through the CDC’s National Center for Health Statistics.
National Oceanic and Atmospheric Administration: climate and weather, including forecasts, and historical records of hurricanes and other newsworthy severe weather events.
Other data portals at various levels of government are emerging. The City and County of San Francisco, for example, was at the forefront of the Open Data movement, establishing DataSF in 2009.
If you need to make comparisons between nations, the World Bank probably has what you need. Its World Development Indicators catalog containing data for more than 7,000 different measures, compiled by the bank and other UN agencies.
You can navigate the site using the search box or using the topics links to the right. When you click on a particular indicator, you are sent to a page that gives options to download the dataset from a link near the top right of the page. The data in some cases goes back as far as 1960, and is listed both by individual country and summarized by regions and income groups.
Other useful sources of data for international comparisons are Gapminder and the UN Statistical Division. For health data in particular, try the Organisation for Economic Co-operation and Development and the World Health Organization.
Search for data on the web
Often, your starting point in searching for data and documents will be Google. It can be worth focusing your queries using Google’s advanced search:
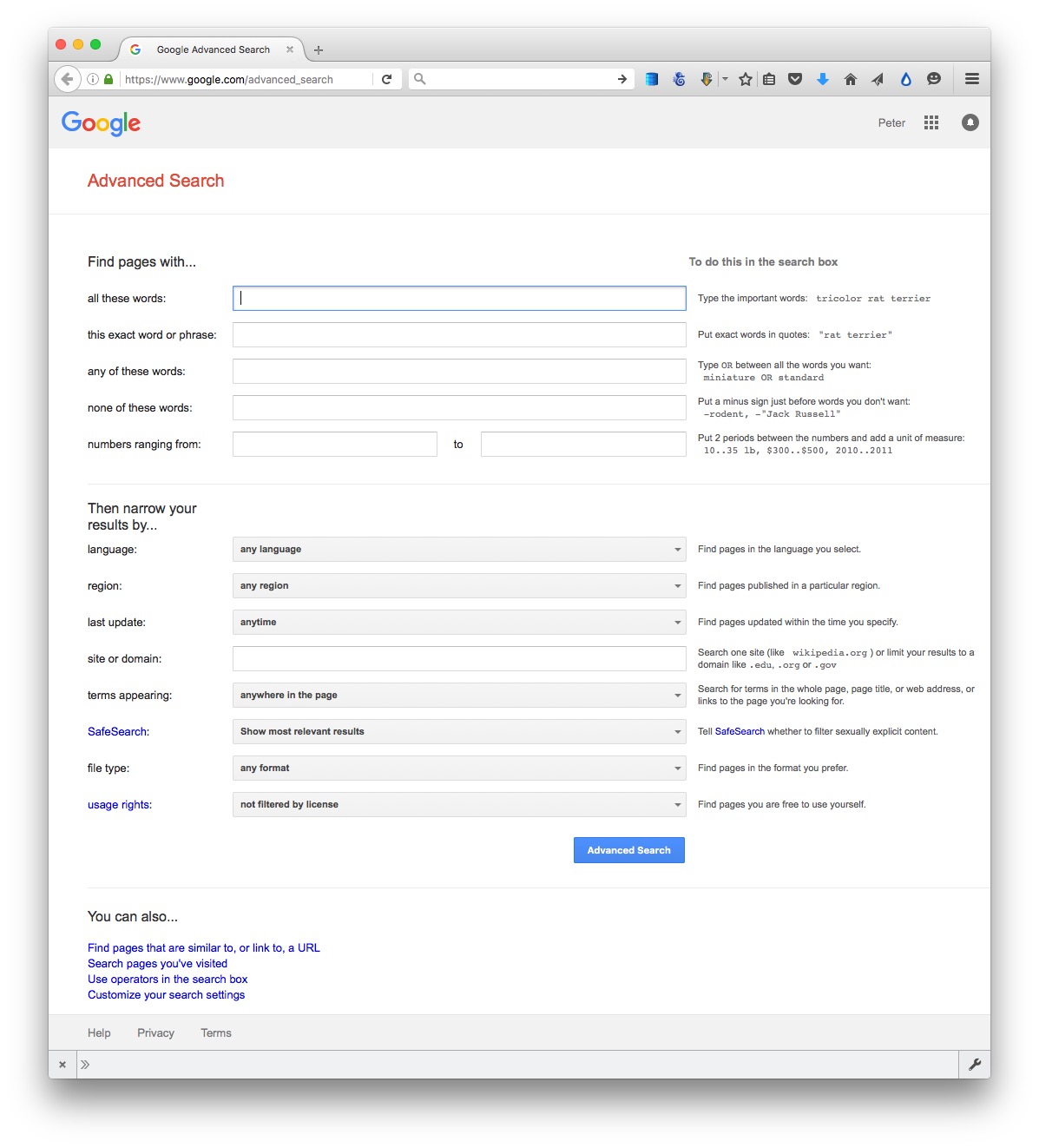
(Source: Google)
The options to search by site or domain and file type can be especially useful when looking for data. For example, the U.S. Geological Survey is the best source of data on earthquakes and seismic risk, so when searching for this information, specifying the domain usgs.gov would be a good idea. You can make the domains as narrow or broad as you like: .edu, for instance, would search the sites of all US academic institutions using that top-level domain; ucsc.edu would search the web pages of this university only.
The file type search offers a drop-down menu, with the options including Excel spreadsheets, and Google Earth KML and KMZ files. These are common data formats, but you are not limited to those on the menu. In a regular Google search, type a space after your search terms followed by filetype:xxx, where xxx is the suffix for the file type in question. For example, dbf will look for database tables in this format. Combining file type and domain searches can be a good way to find data an agency has posted online — some of which may not otherwise be readily accessible.
Searching for PDFs and PPT presentations can be a good way to find documents that may not otherwise be easy to find.
One common data format doesn’t show up file type searches. Geographical data is often made available as “shapefiles.” Because they consist of multiple files that are usually stored in compressed folders, shapefiles can’t readily be searched using a file type suffix, but they can usually be found by adding the terms “shapefile” or “GIS data” to a regular Google search.
Search online databases
Many important public databases can be searched online, and some offer options to download the results of your queries. Most of these databases give a simple search box, but it’s always worth looking for the advanced search page, which will offer more options to customize your search. Here, for example, is the advanced search page for ClinicalTrials.gov:
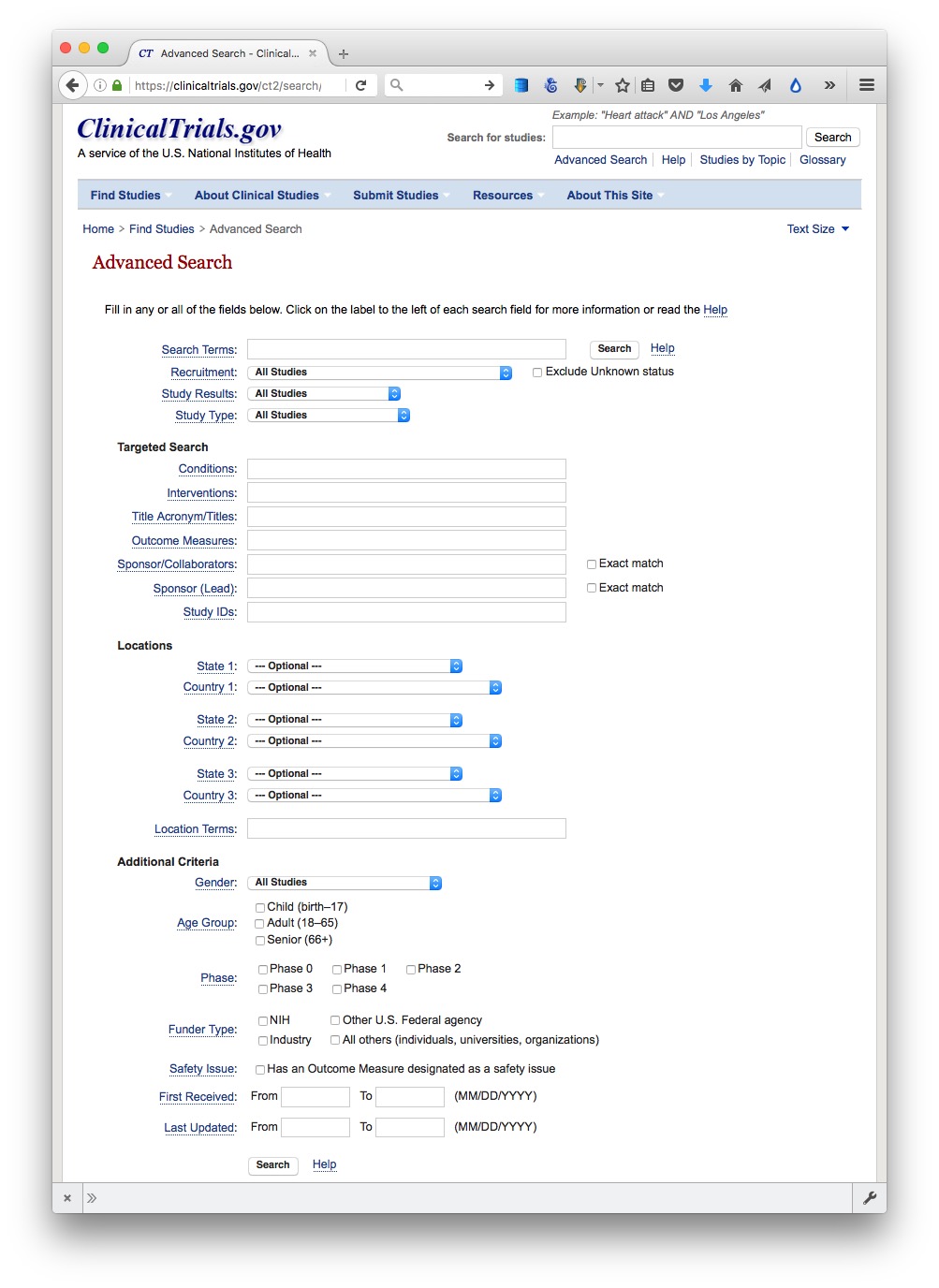
(Source: ClinicalTrials.gov)
When you start working with a new online database, take some time to familiarize yourself with how its searches work: Read the Help or FAQs, and then run test searches to see what results you obtain. Here, for example, is the “How To” section of ClinicalTrials.gov.
Many online databases can be searched using Boolean logic, using the operators AND, OR and NOT to link search terms together. So find out how a particular database uses Boolean logic — and the default settings that it will use if you list search terms without any Boolean operators.
Putting search terms in quote marks often searches for a specific phrase. For example, searching for “heart attack” on ClinicalTrials.gov will give only give results in which those two words appear together; leaving out the quote marks will include any trial in which both words appear.
Also find out whether the database allows “wildcards,” symbols such as * or % that can be dropped into your search to obtain results with variations on a word or number.
Look for download options — and know when you are hitting the wall
Having run a search on an online database, you will usually want to download the results, so look for the download links or buttons.
A common problem with online databases, however, is that they may impose limits on the number of results that are returned on each search. And even when a search returns everything, there may be a limit on how many of those results can be downloaded to your own computer.
If broad searches on a database keep returning the same number of results, that is a sign that you are probably running up against a search limit, and any download will not contain the complete set of data that you are interested in. However, you may be able to work out ways of searching to obtain all of the data in chunks.
Download the entire database
Downloading an entire database, where this is allowed, frees you from the often-limited options given on an online advanced search form: You can then upload the data into your own database software, and query it in any way that you want. We will learn how to do this next week.
So always look for ways to grab all of the data. One trick is to run a search on just the database’s wildcard character, or with the query boxes left blank. If you do the latter at ClinicalTrials.gov, for instance, your search will return all of the trials in the database, which can then be downloaded using the options at the bottom of the results page.
Other databases have an online search form, but also have a separate link from where data to be downloaded in its entirety, usually as a text file or series of text files. One example is Bioresearch Monitoring Information System, which lists doctors and other researchers involved in testing experimental drugs being considered for marketing approval by the Food and Drug Administration. It can be searched online here, but can also be downloaded in full from here.
Note that large text files are again often stored in compressed folders, so may be invisible to a Google search by file type.
Automate downloads of multiple data files
Often data or documents don’t reside in a single searchable database, but instead exist online as a series of separate files. In such cases, clicking on each link is tedious and time-consuming. But you can automate the process using the DownThemAll! Firefox add-on.
To illustrate, go to Gapminder’s data catalog, and select All indicators. The webpage now includes links to more than 500 downloadable spreadsheets. Right-click and select DownThemAll!....
At the dialog box, you can choose where to save the files, and to filter the links to select just the files you want. There are check boxes to download documents or images, and so on. In this case, all the spreadsheet downloads contain the text xls, defining the format of the download from Google Sheets, so Fast Filtering using the term xls will correctly identify these downloads:
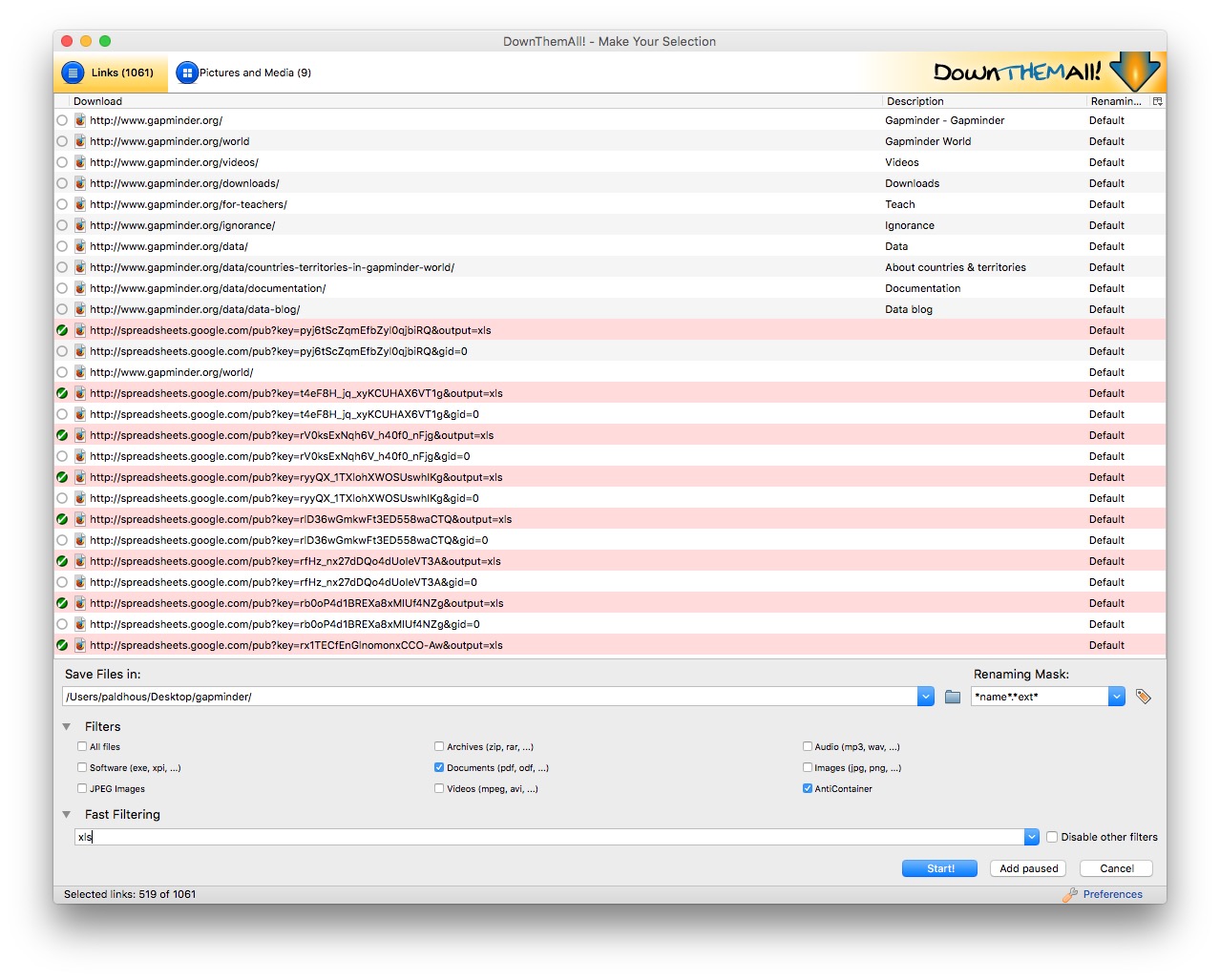
Extract data from tables on the web
On other occasions, data may exist in tables on the web. Copying and pasting data from web tables can be tricky, but the Table2Clipboard Firefox add-on simplifies the process.
Before using the add-on, select Tools>Table2Clipboard and choose the following options under the CSV tab:
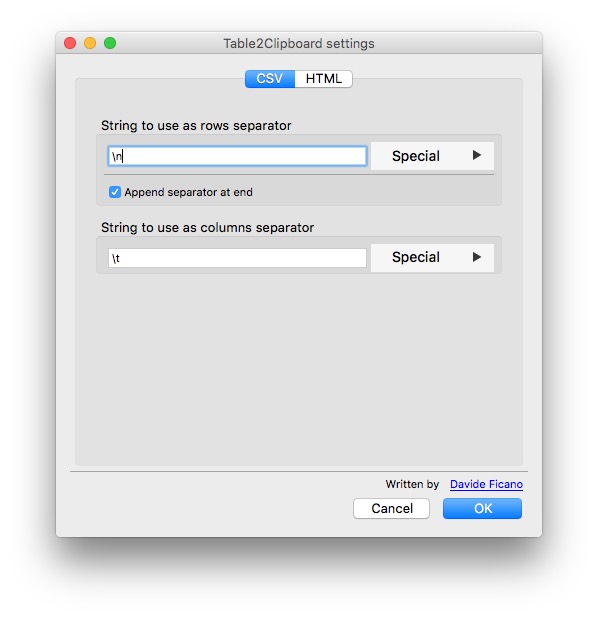
This will ensure that each row in the extracted data is put on a new line, and each column is separated by a tab.
To illustrate what Table2Clipboard does, go to this table showing the budget history for components of the National Institutes of Health.
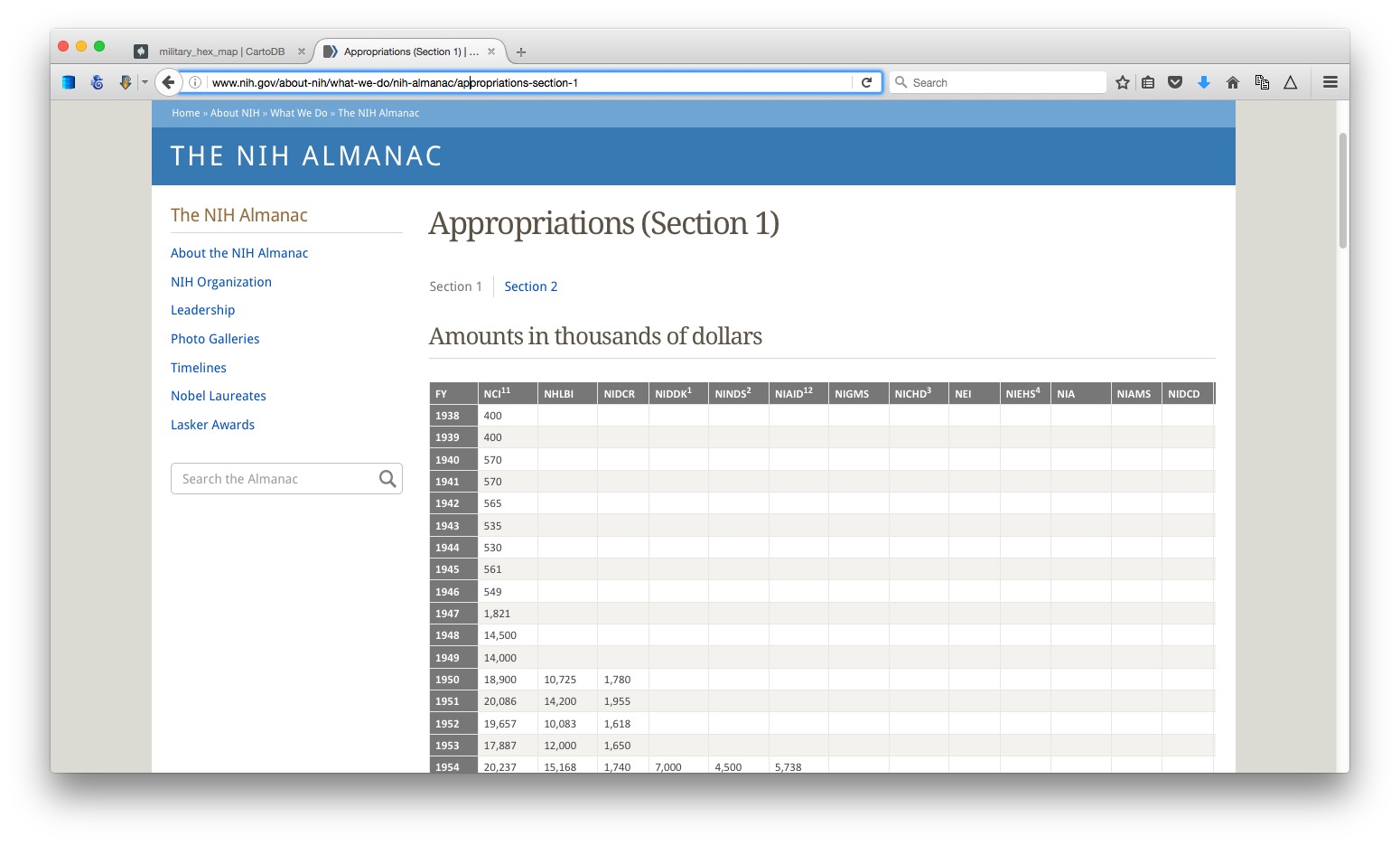
(Source: NIH)
Right-click anywhere within it and select Table2Clipboard>Copy whole table.
You can now paste the data into an empty text file, or into a spreadsheet. We’ll paste it into a spreadsheet.
This table is in two parts, so click on the Section 2 link, and repeat the process to grab all the data.
Manipulate urls to expose the data you need
As you search for data using web query forms, make a habit of looking at what happens to the url. Often it will contain patterns detailing the search you have run, and it will be possible to alter the data provided by manipulating the url. This can be quicker than filling in search forms. In some cases it may even reveal more data than default search options will allow.
To illustrate how this works, go to the ISRCTN clinical tral registry, and then navigate to the advanced search page. Enter cancer under Condition and note that almost 2,000 trials are returned.
The url should now have changed to the following:
http://www.isrctn.com/search?q=&filters=condition%3Acancer&searchType=advanced-search
Notice that the default is to display 10 results per page, and then change the view to see the maximum of 100 trials allowed by the dropdown menu. The url should now read:
http://www.isrctn.com/search?pageSize=100&sort=&page=1&q=&filters=condition%3Acancer&searchType=advanced-search
Now change that url to:
http://www.isrctn.com/search?pageSize=2000&sort=&page=1&q=&filters=condition%3Acancer&searchType=advanced-search
Having done so, all of the registered clinical trials involving cancer should now be displayed on a single page. We could now use DownThemAll! to download all of the individual web pages describing each of these trials, or we could use this url as the starting point to scrape data from each of those pages.
Use application programming interfaces (APIs)
Websites like the ISRCTN clinical trial registry are not expressly designed to be searched by manipulating their urls, but some organizations make their data available through APIs that can be queried by constructing a url in a similar way. This allows websites and apps to call in specific chunks of data as required, and work with it “on the fly.”
To see how this works, go to the U.S. Geological Survey’s Search Earthquake Archives page, where we will search for all earthquakes with a magnitude of 5 or greater that occured witin 6,000 kilometers of the geographic center of the contiguous United States, which this site tells us lies at a latitude of 39.828175 degrees and a longitude of -98.5795 degrees. We will initially ask for the data in a format called GeoJSON (a variant of JSON, a common format used to trasmit data over the web). Enter 1960-01-01T00:00:00 under Start for Date & Time boxes so that we obtain all recorded earthquakes from the beginning of 1960 onward. The search form should look like this:
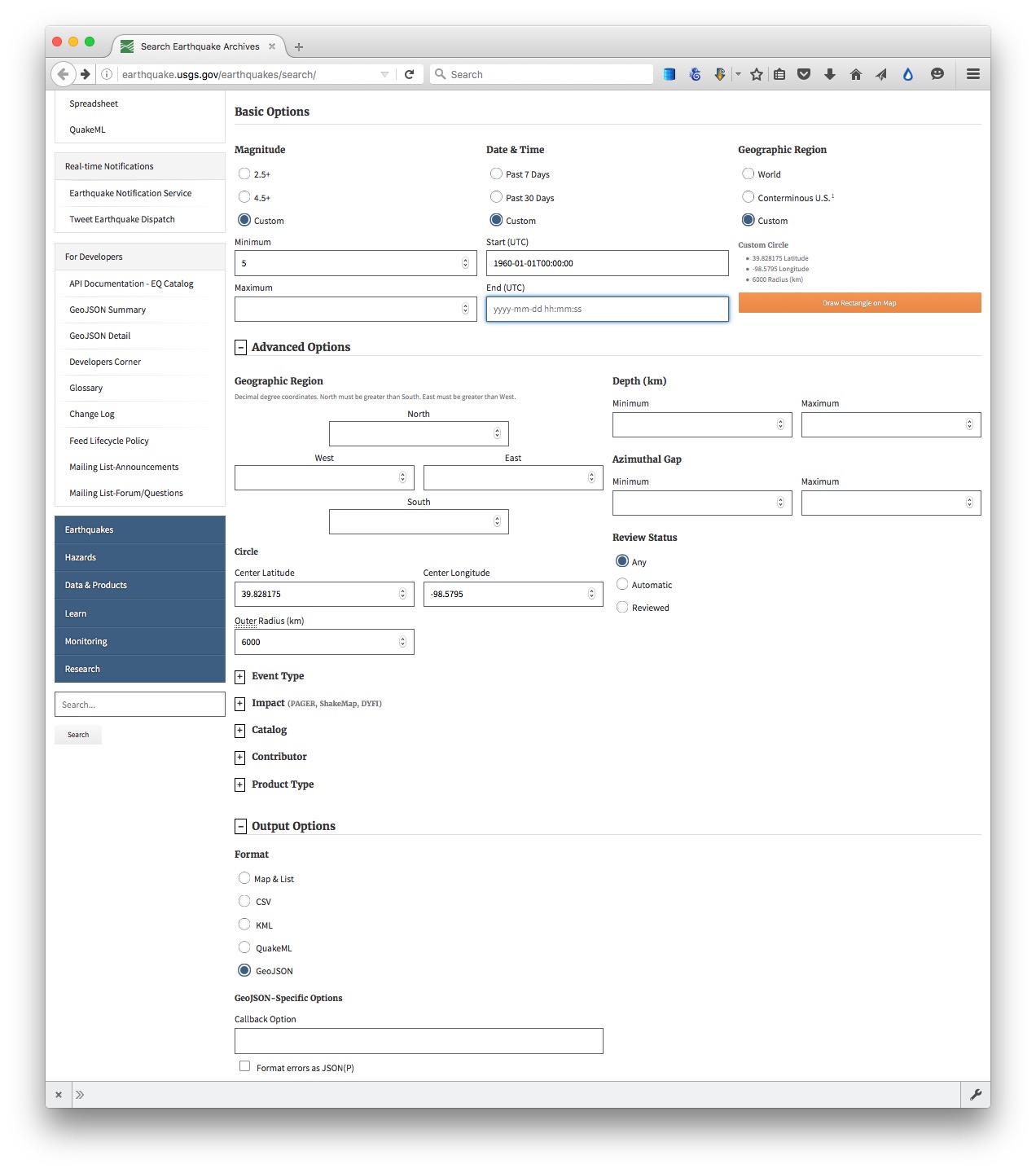
(Source: U.S. Geological Survey)
You should recieve a quantity of data at the following url:
http://earthquake.usgs.gov/fdsnws/event/1/query?starttime=1960-01-01T00:00:00&latitude=39.828175&longitude=-98.5795&maxradiuskm=6000&minmagnitude=5&format=geojson&orderby=time
See what happens if you append -asc to the end of that url: This should sort the the earthquakes from oldest to newest, rather than the default of newest to oldest. Here is the full documentation for querying the earthquake API by manipulating these urls,
Now remove the -asc and replace geojson in the url with csv. The data should now download in CSV format.
Scrape data from the web
Sometimes you will need to compile your own data from information that is spread across a series of webpages, or maintained in a database that doesn’t allow simple downloads of the data or API access. This is where web scraping comes in.
Using programming languages such as Python or R, it is possible to write scripts that will pull data down from many webpages, or query web search forms to download an entire database piece by piece.
Web scraping by coding is beyond the scope of this class. However, the underlying process is simple to understand: Identify the patterns you would need to follow if collecting the data manually, then write a program to automate the process and write the results to a data file. That often means experimenting to reveal the most efficient way of exposing all of the data you require.
We have already been performing some of the elements of web scraping, by manipulating urls on web search forms and downloading the individual links en masse.
There are a number of tools that allow non-programmers to scrape data from the web. These include the Windows-only Helium Scraper, and the web-based Import.io. In this class, we will use OutWit Hub. You can use the free version to see its capabilities. A license to the full version cost $89 at the time of writing, so is considerably cheaper than an Import.io account.
To demonstrate webscraping, we will download data on disciplinary actions against doctors in the state of New York.
Navigate to this page, which is the start of the list. Then click on the Next Page link, and see that the url changes to the following:
https://w3.health.ny.gov/opmc/factions.nsf/byphysician?OpenView&Start=30
Notice that the first entry on this list is actually the last entry on the previous one, so this url is the next page with no duplicates:
https://w3.health.ny.gov/opmc/factions.nsf/byphysician?OpenView&Start=31
Experiment with different numbers at the end of the url until you find the end of the list. As of writing, this url exposed the end of the list, revealing that there were 7569 disciplinary actions in the database.
https://w3.health.ny.gov/opmc/factions.nsf/byphysician?OpenView&Start=7568
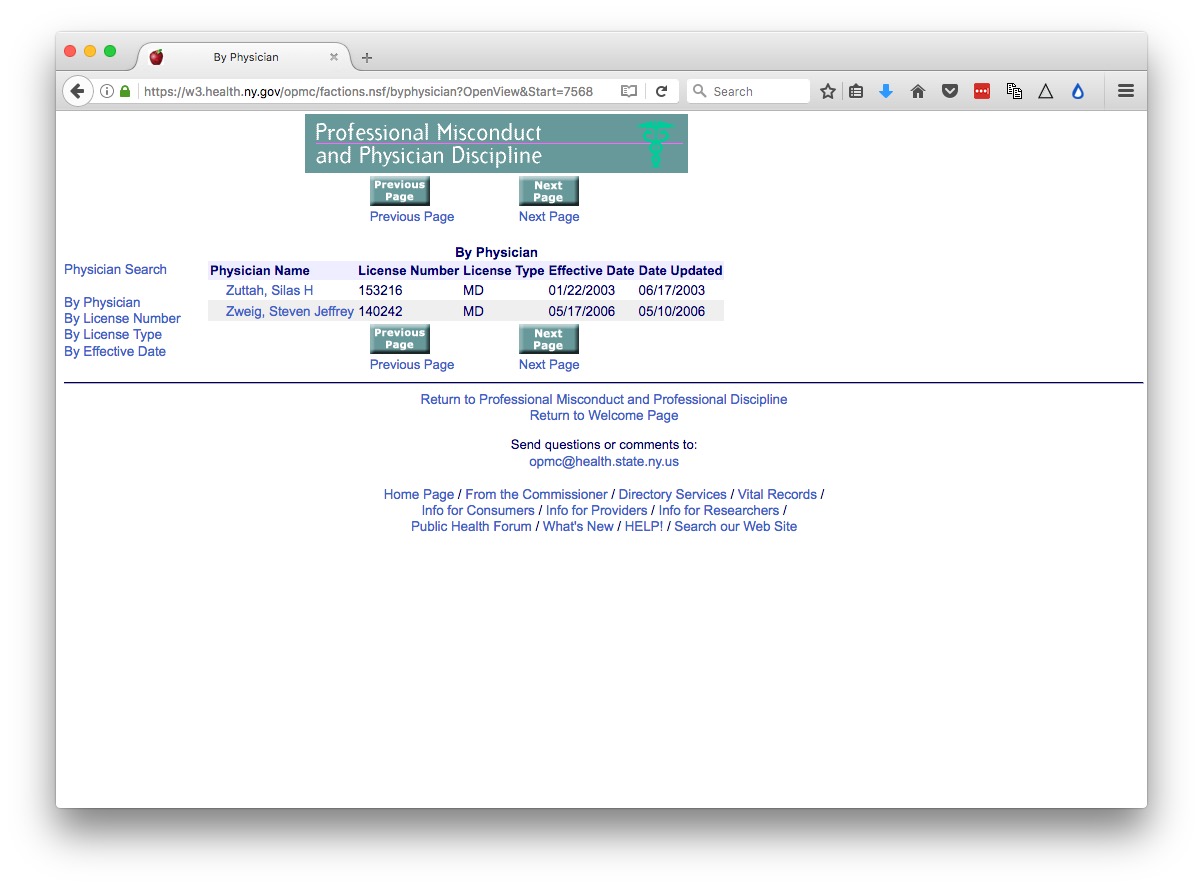
Click on the link for the last doctor’s name, and notice that data on each disciplinary action, plus a link to the official documentation as a PDF, are on separate web pages. So we need to cycle through all of these pages to grab data on every disciplinary action.
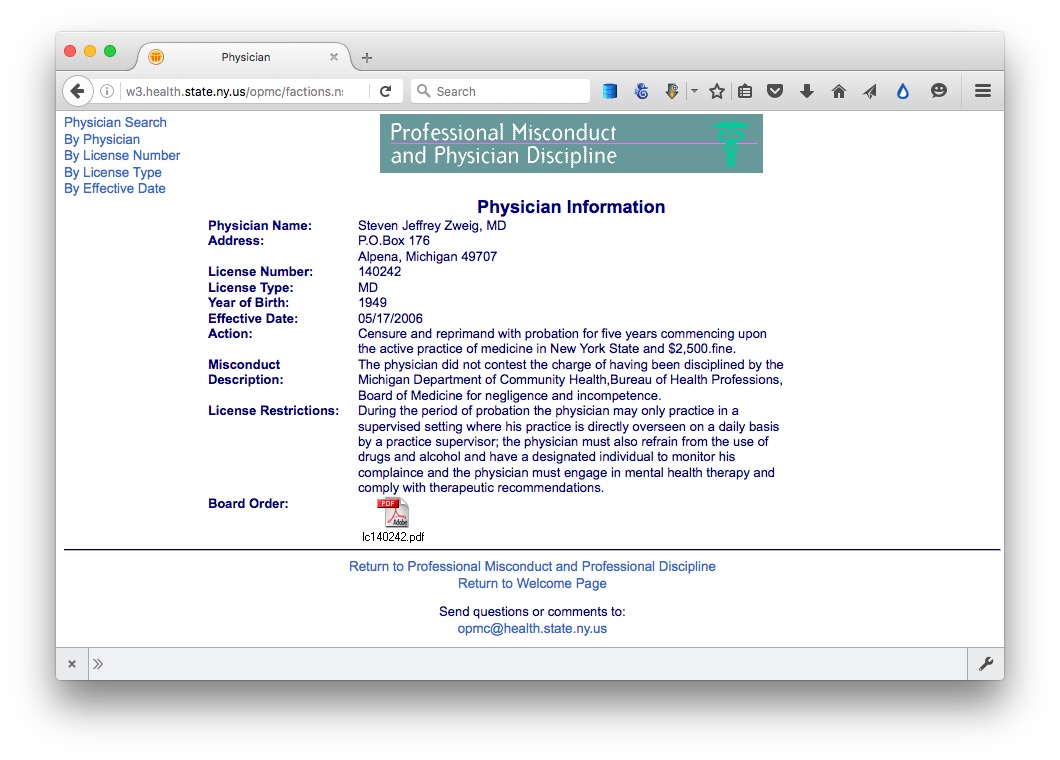
These disciplinary action pages have urls of the following form:
https://w3.health.ny.gov/opmc/factions.nsf/58220a7f9eeaafab85256b180058c032/35e1ad86e4a5ec26852571560046127f?OpenDocument
The first step is to cycle through the entire list, scraping all of the urls for the individual pages. Then we need to set up a second scraper to grab the information from each of the individual disciplinary action pages, using this list of urls.
Outwit Hub can usually recognize a when a website is a paginated list, and can automatically follow “next page” links.
To scrape the list of urls, navigate in Outwit Hub to the first page in the list of disciplinary actions:
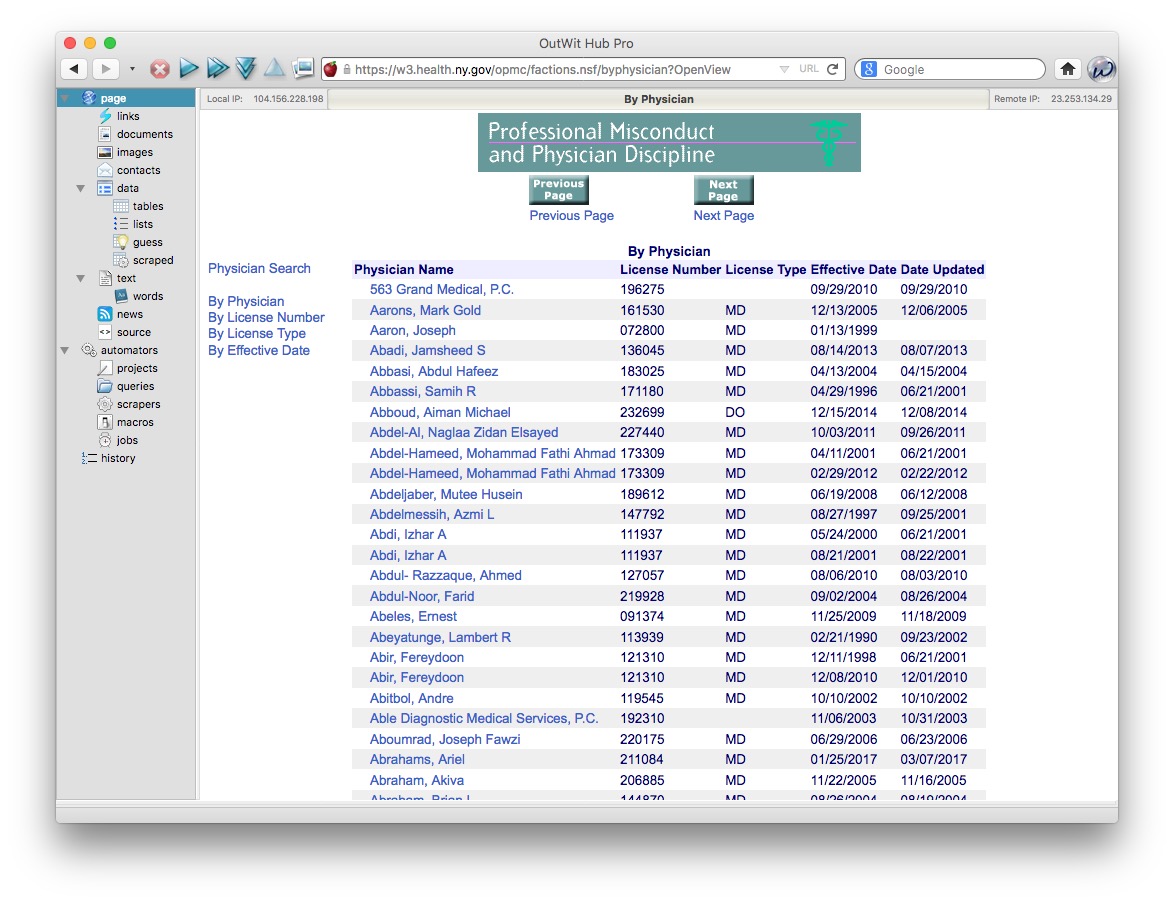
Now select automators>scrapers from the panel at left:
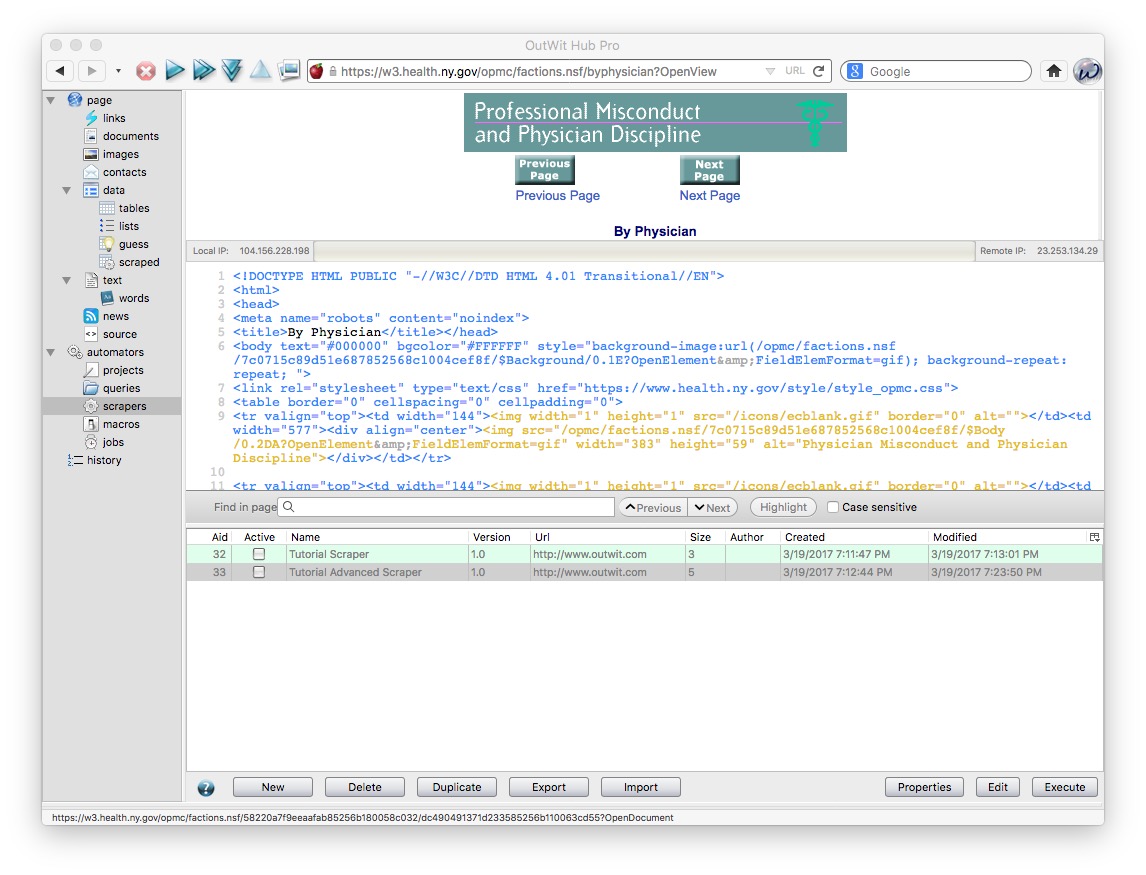
Notice that this exposes the HTML code for the page.
Click the New button at the bottom, and give the scraper an appropriate name, such as NY doctor discipline urls. You will now see a screen that allows you to extract data/text from the page, according to markers in the HTML code before and after the target.
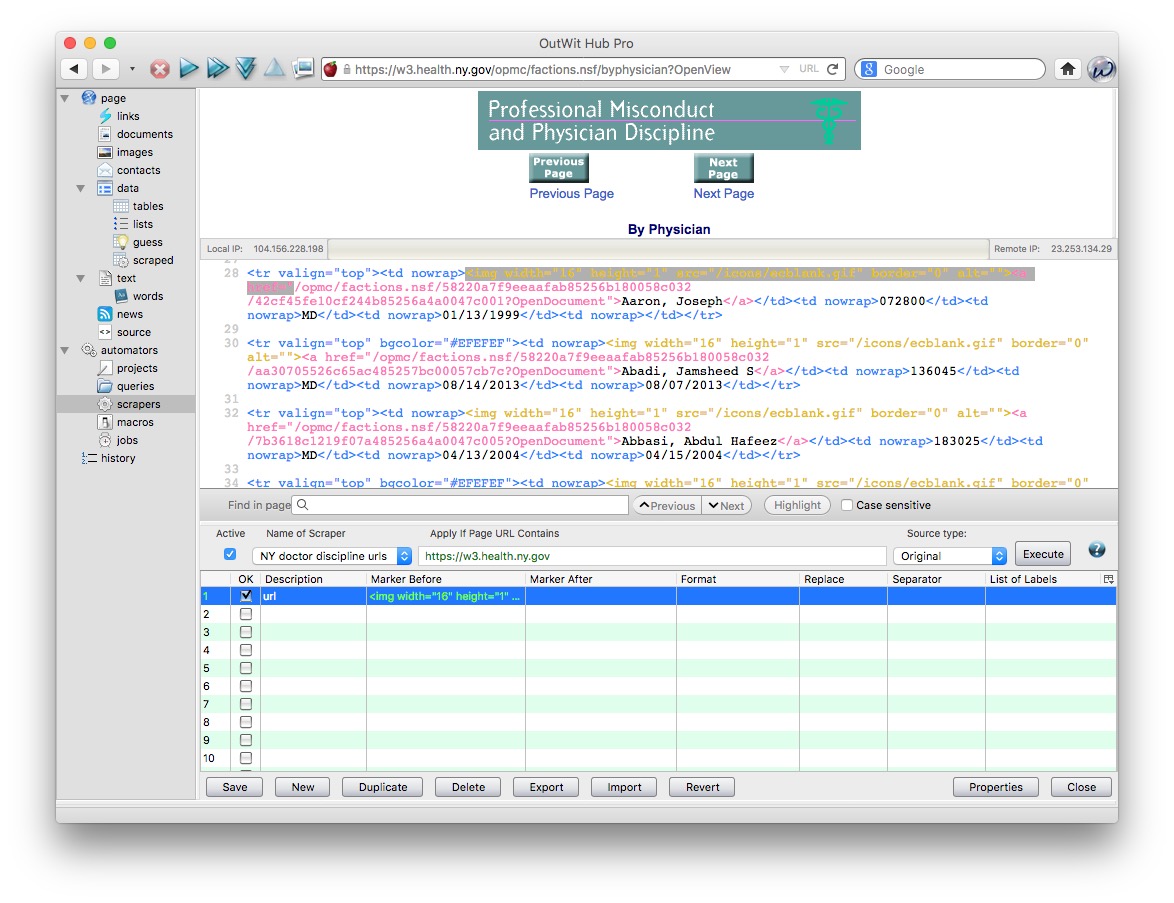
Scroll through the HTML, and highlight this section of code, which appears before the link to each disciplinary page (this link is the full url for the disciplinary action page, minus the stem: https://w3.health.ny.gov).
<img width="16" height="1" src="/icons/ecblank.gif" border="0" alt=""><a href="
In the row numbered 1 in the instructions for your scraper, enter url under Description and that HTML code under Marker Before:
After each url the link closes with the following:
">
So copy that under Marker After and your scraper is ready to run:
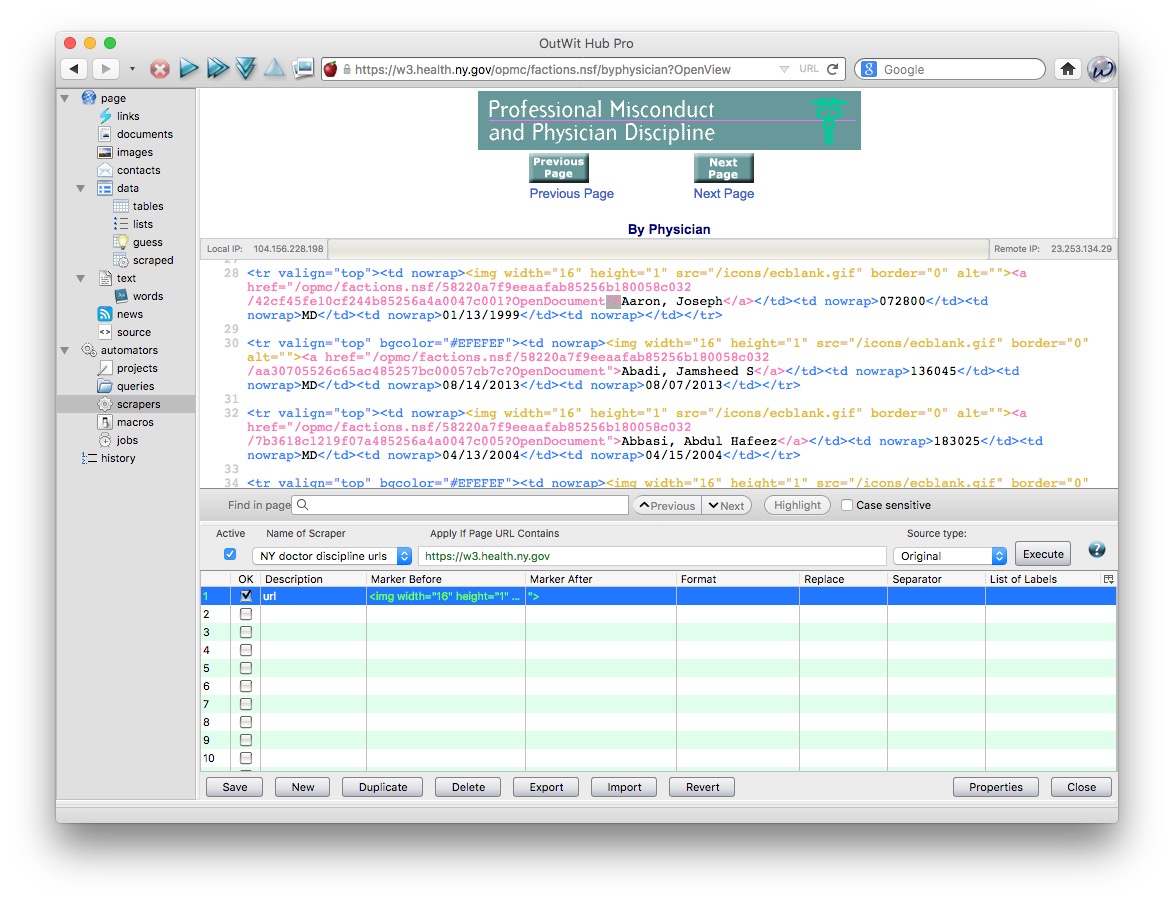
Click Save and then Execute and you should see a screen like this under data>scraped, which has captured the 30 links on the page:
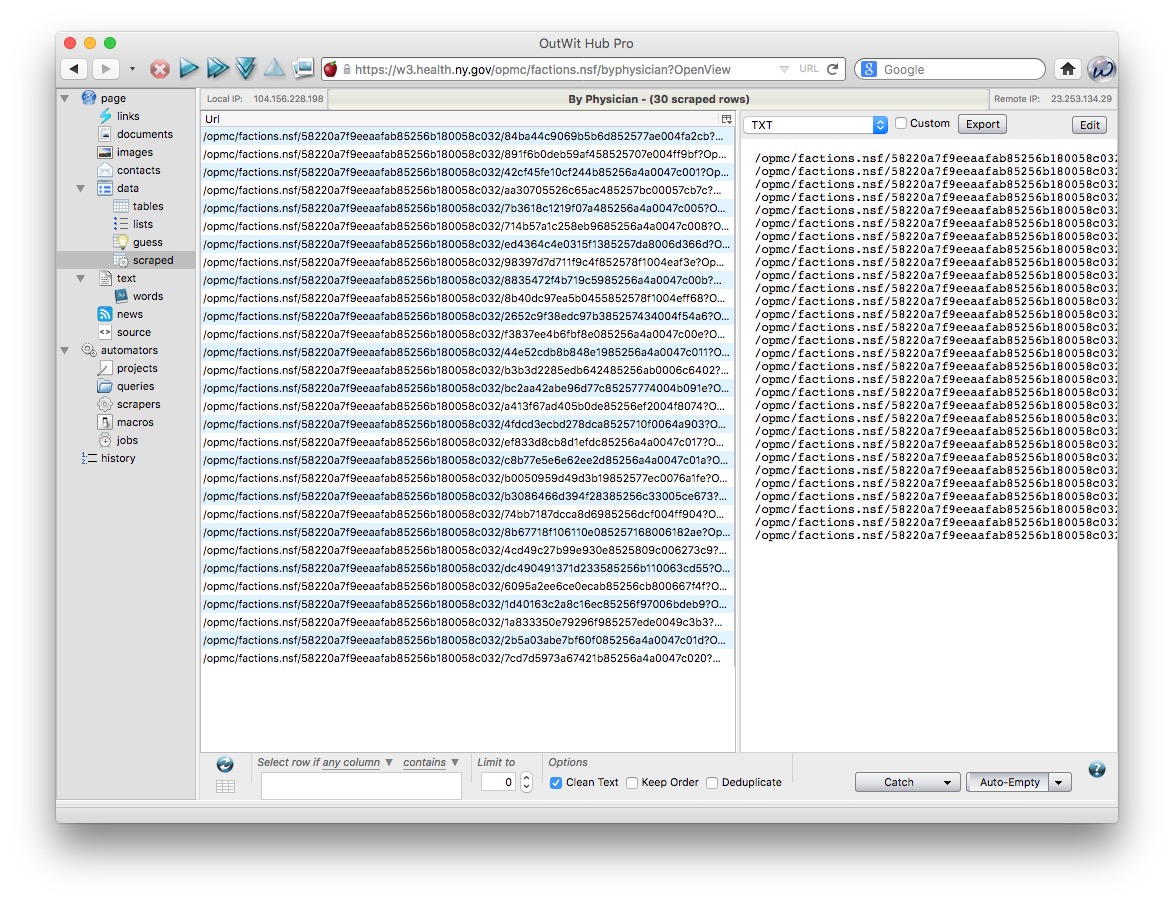
On this page, check the Deduplicate box (this will eliminate the duplicated urls that would otherwise result from this site’s overlapping pagination), then set the two buttons with drop down menus at bottom right to Catch on Demand and Empty on Demand. This ensures that the scraped data is appended into a single file for export at the end.
Having completed the set-up, click this control button at the top, which will automatically follow the “next page” links and scrape the urls from each page in sequence:

Running the full scraper will take some time. When it is complete, notice that the right-hand export panel under data>scraped has a series of dropdown menus, including CSV, TXT, SQLite and Excel. We will export as TXT, giving a list in a single text file.
One you are sure that the text file has saved correctly, click the Empty button under data>scraped to clear the results of the scrape.
In an empty spreadsheet (I used Libre Office Calc, it should also work in Excel), paste the list of urls from the text document into column B. Then copy the stem for the urls into cell A1:
https://w3.health.ny.gov
Hover over the bottom right corner of this cell, until the cursor turns into a cross, then double-click to autofill down the entire column.
Now enter the following into cell C1:
=CONCATENATE(A1,B1)
This will append the two together to create the full url. Again use autofill to copy the formula down the column and create the urls for each of the disciplinary actions.
Now save the spreadsheet as an HTML file (using File>Save As) to create a web page, which when opened in a browser should look like this:
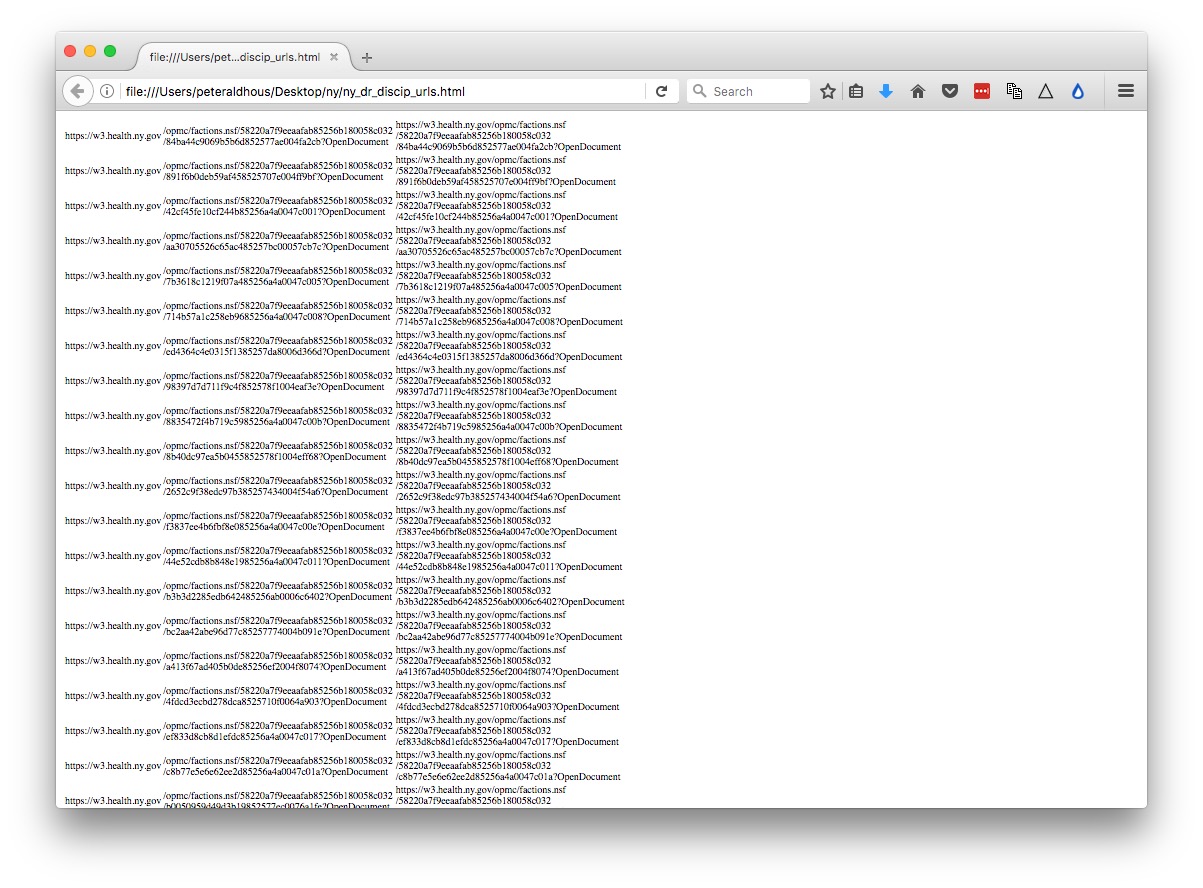
We will use this file, which contains an HTML table with the urls, to direct our second scraper, which we now need to set up.
In Outwit Hub, navigate to one of the displinary action pages and select automators>scrapers. Click New and give the scraper an appropriate name, such as NY doctor disciplinary actions.
Most of the data we want to extract follows the heading and a colon, for example:
Physician Name:
These entries are each followed by this HTML code:
</font></td></tr>
The PDF of the board order is at an link preceded in the HTML code by:
Board Order:</font></b></td><td width="427"><Text><a style="display: inline-block; text-align: center" href="
The link is followed by:
" title
So set the scraper up like this:
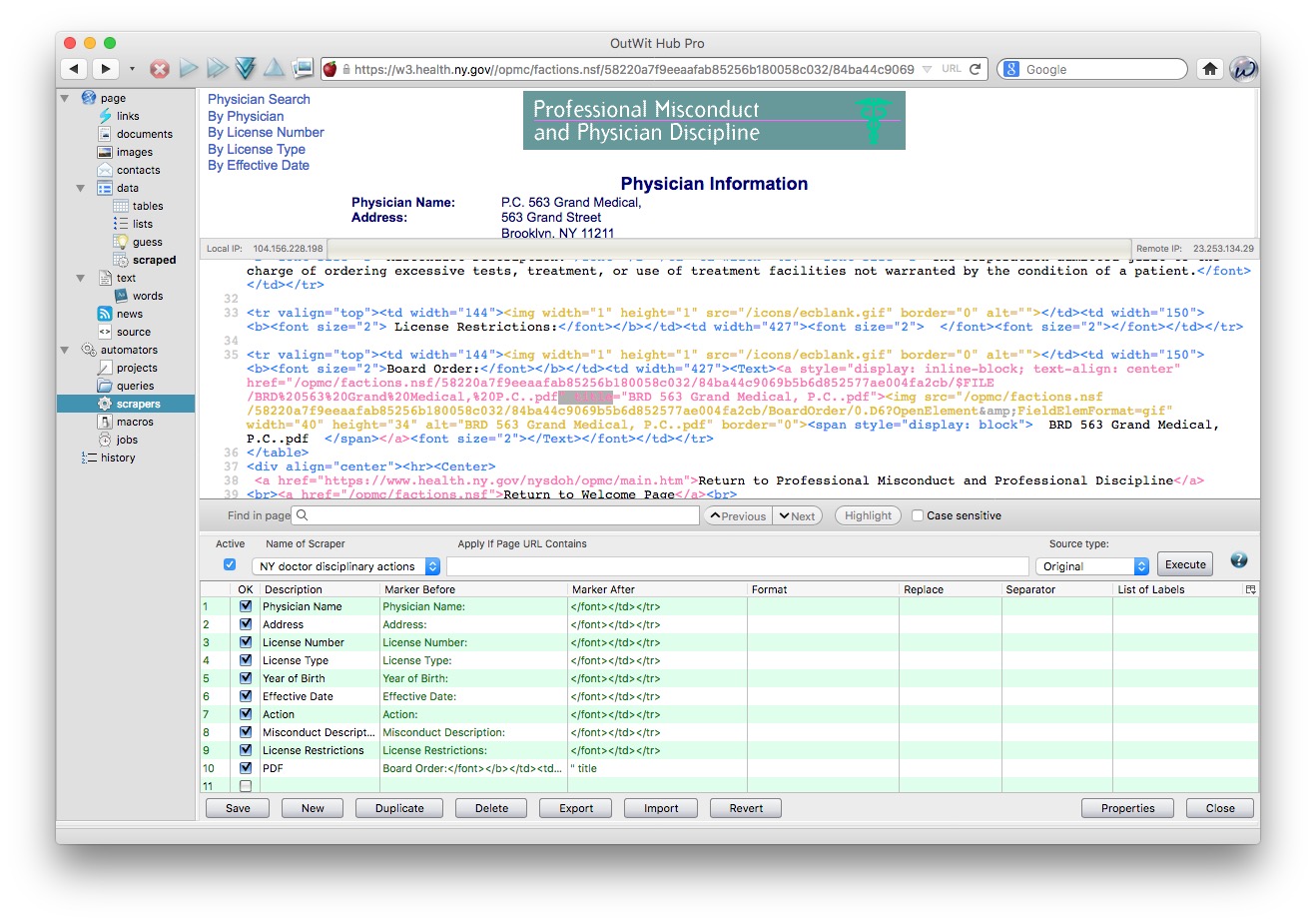
Click Save, then switch to data>tables. From the top menu in Outwit Hub, select File>Open ... and open the HTML file with the urls.
When the file opens, the urls should be in Column 6 of the table. Select the first, then ⌘-A (Mac) or Crtl-A (Windows) to select all the urls in the column:
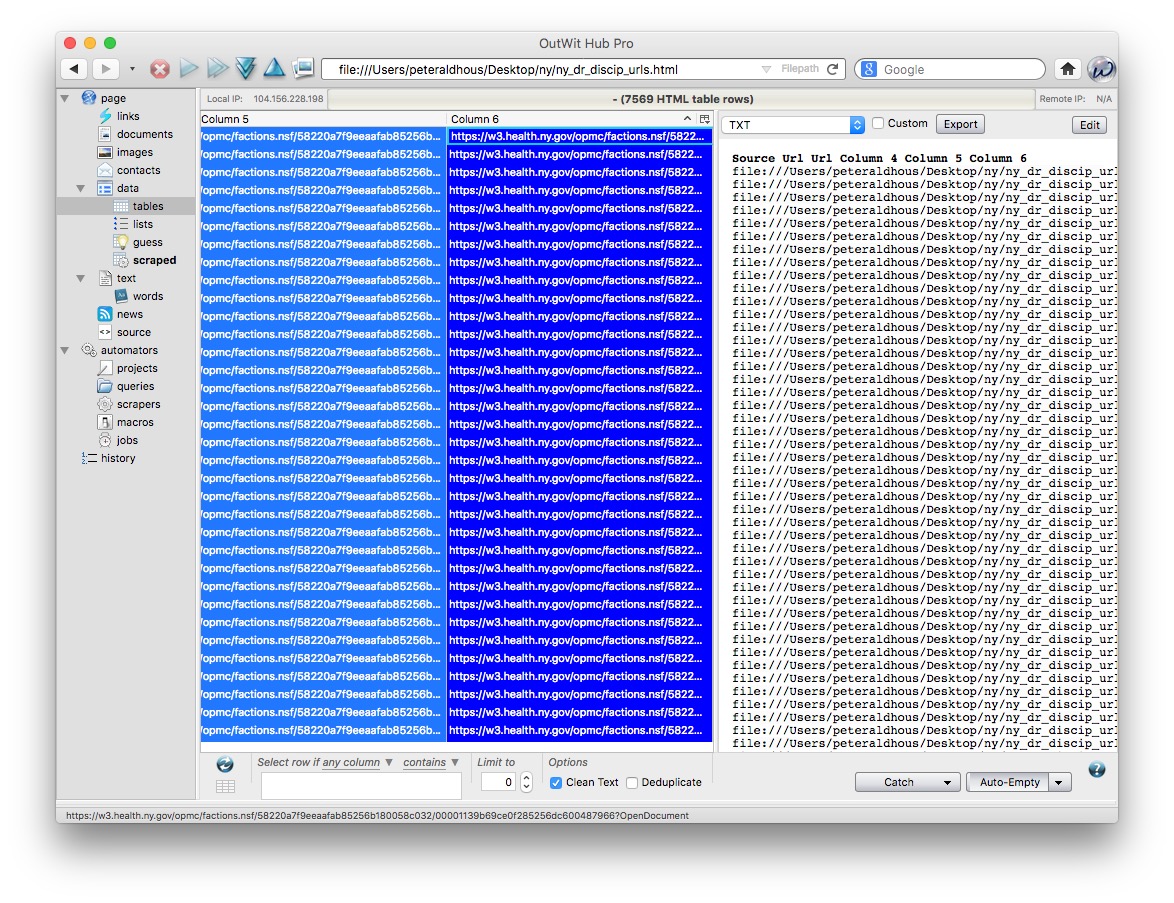
Again, set the two buttons with drop down menus at bottom right to Catch on Demand and Empty on Demand.
Now right-click, and select Auto-Explore Pages>Fast Scrape> and the scraper we just set up:
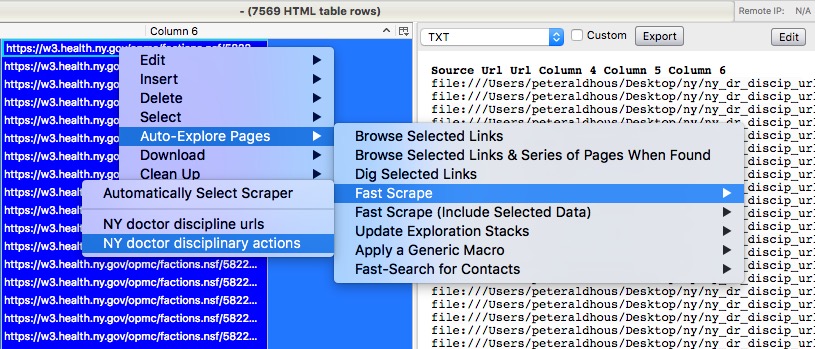
The scraper should now start to run:
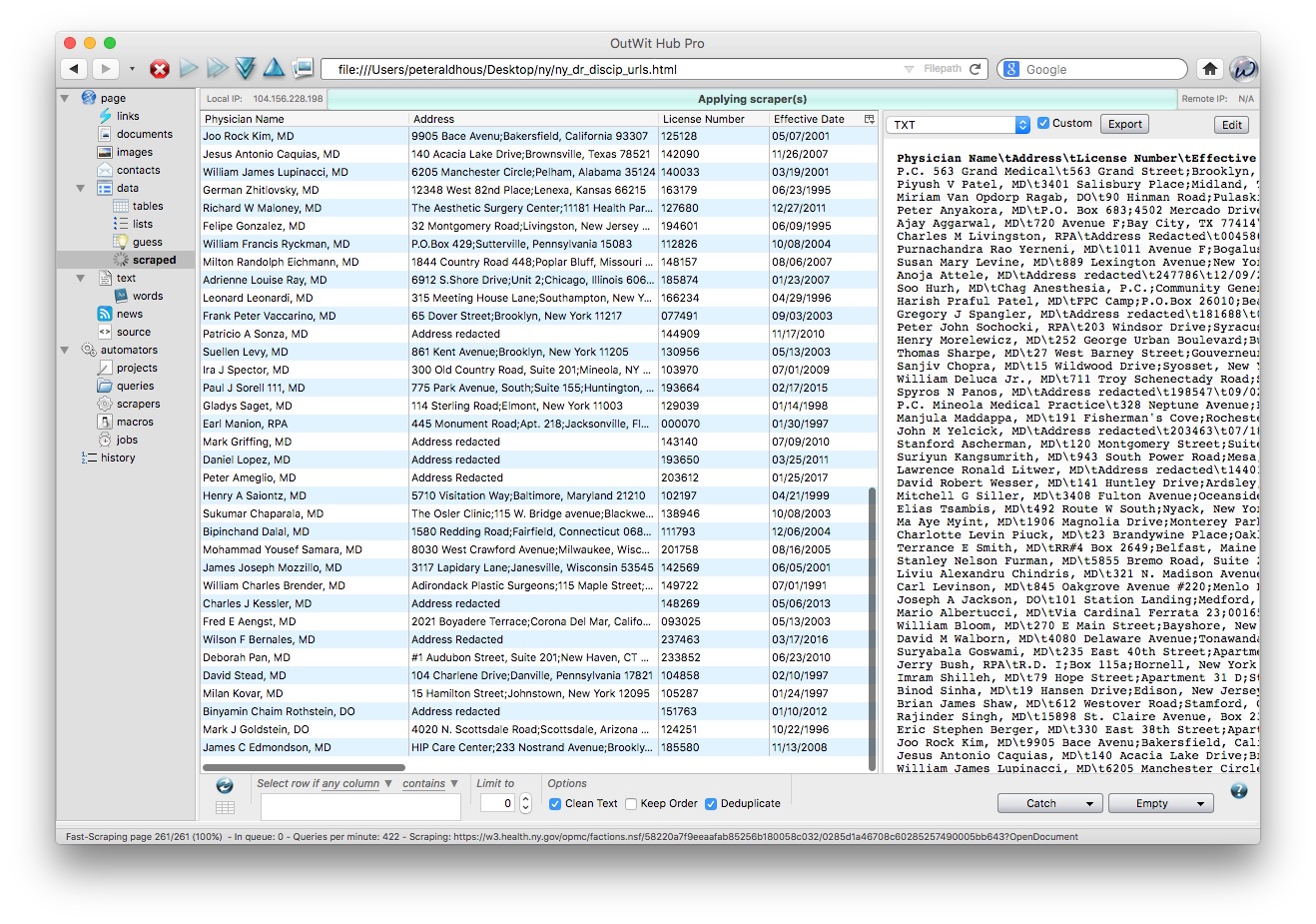
The full scrape will again take some time to run. When it is completed, export the data as a TXT file and an Excel spreadsheet.
PDFs: The bane of data journalism
Some organizations persist in making data available as PDFs, rather than text files, spreadsheets or databases. This makes the data hard to extract. While you should always ask for data in a more friendly format — ideally a CSV or other simple text file — as a data journalist you are at some point likely to find yourself needing to pull data out of a PDF.
For digital PDFs, Tabula is a useful data extraction tool — however it will not work with PDFs created by scanning the original document, which have to be interpreted using Optical Character Recognition (OCR) software.
Also useful is the online service Cometdocs. While it is a commercial tool, members of Investigative Reporters and Editors can obtain a free account. Cometdocs can read scanned PDFs, however its accuracy will vary depending on how well the OCR works on the document in question.
Adobe Acrobat Pro will also perform OCR on scanned PDFs.
Here is a useful set of resources detailing more advanced tools for dealing with hard-to-parse PDFs.
Further reading/resources
Paul Bradshaw. Scraping For Journalists
Dan Nguyen. The Bastards Book of Ruby
I use R or Python rather than Ruby, but this book provides a good introduction to the practice of web scraping using code, and using your browser’s web inspector to plan your scraping approach.